
Project Tafsiri: Bridging Indigenous Languages and AI
- Dr. Moody Amakobe

- Apr 8
- 12 min read

The Role of Indigenous Languages in Training African-Centric AI Models
Introduction
Artificial Intelligence (AI) is rapidly reshaping how societies interact with technology, from voice assistants and search engines to automated translation and smart healthcare systems. Yet, as Africa embraces this digital transformation, a critical gap persists: the absence of indigenous African languages in the core of AI systems. Most AI tools today are trained primarily on English, French, and other dominant global languages, leaving the continent's rich linguistic diversity vastly underrepresented.
Africa is home to more than 2,000 languages, many of which are deeply embedded in local culture, identity, and knowledge systems. However, these languages rarely feature in the datasets used to train natural language processing (NLP) models or other AI applications. As a result, AI systems often perform poorly for millions of Africans, especially those who communicate primarily in indigenous languages.
This exclusion is more than a technical oversight; it is a digital marginalization with far-reaching consequences. It limits access to AI-driven services like virtual healthcare, digital banking, and education, and risks amplifying existing inequalities. For AI to be truly inclusive and beneficial in Africa, it must understand, process, and generate African languages natively.
Digital Language Gaps and Their Consequences
Most modern AI systems rely heavily on massive datasets for training. Unfortunately, indigenous African languages often lack the large, digitized corpora that power these models. While English, Mandarin, and a handful of European languages dominate the internet and AI datasets, languages like Wolof, Igbo, or Amharic remain largely invisible in digital spaces.
This gap has real-world implications. Virtual assistants like Siri or Alexa may fail to recognize African names or respond accurately to local dialects. Automated translation tools struggle with even the most commonly spoken African languages. This leads to technology that is not just unhelpful but sometimes completely unusable for African populations.
Moreover, when people are forced to interact with AI in a second or third language, it creates barriers to access, reinforces linguistic hierarchies, and diminishes cultural identity. Students may struggle with educational AI tools that don't understand their native language, elderly populations may be completely excluded from digital services, and cultural nuances embedded in indigenous languages are lost in translation.
Challenges in Training AI for Indigenous Languages

Developing AI systems that understand indigenous languages is not a simple task. Many of these languages are considered "low-resource," meaning they lack the large-scale, high-quality data needed to train effective models. There are several reasons for this:
- Orality: Many African languages are primarily spoken rather than written, making it difficult to source large text corpora.
- Standardization: Some languages have multiple dialects or lack standardized grammar, which complicates computational processing.
- Lack of digitized content: Historical, educational, and cultural materials are often not digitized or publicly available.
- Multilingualism: In many African contexts, people switch between multiple languages, creating mixed-language data that is harder to classify and train.
These challenges make it expensive and time-consuming to develop indigenous language datasets, but they are not insurmountable.
The Economic and Social Imperative
The exclusion of indigenous languages from AI systems represents a significant economic opportunity cost. Africa's digital economy is projected to reach $712 billion by 2030, yet this growth potential is constrained when large segments of the population cannot effectively interact with digital technologies in their native languages.
Consider the impact across key sectors:
- Healthcare: AI-powered diagnostic tools and telemedicine platforms could save lives in remote areas, but only if they can communicate effectively with local populations.
- Education: Adaptive learning systems could revolutionize education accessibility, but students learn best in their mother tongue, especially in early childhood development.
- Agriculture: AI-driven crop management and weather prediction systems could boost food security, but smallholder farmers need these tools in languages they understand.
- Financial Services: Mobile banking and digital payment systems could drive financial inclusion, but trust and adoption require communication in local languages.
Cultural Preservation Through Technology
Indigenous languages are repositories of traditional knowledge, cultural practices, and worldviews that have evolved over centuries. When these languages are excluded from digital spaces, we risk losing not just linguistic diversity, but entire knowledge systems.
AI systems trained on indigenous languages can help preserve and revitalize these linguistic treasures. They can:
- Archive oral traditions and folklore
- Facilitate intergenerational knowledge transfer
- Support language learning and education
- Enable cultural content creation and distribution
Introducing Project Tafsiri

Project Tafsiri (Swahili for "translation") is an initiative designed to bridge the gap between Africa's indigenous languages and modern AI technology. The project aims to create comprehensive, culturally-aware AI systems that can understand, process, and generate content in African languages with the same sophistication available for major global languages.
The vision of Project Tafsiri extends beyond simple translation. We are building AI systems that understand cultural context, preserve traditional knowledge, and empower communities to access modern technology without abandoning their linguistic heritage.
Starting with Luhya: The LuhyaAI Proof of Concept
As a foundational step in this larger vision, I have developed LuhyaAI, a specialized chatbot and language model focused on the Luhya language cluster spoken by over 6 million people in Kenya, Uganda, and Tanzania.
Luhya represents an ideal starting point for several reasons:
1. Significant speaker population: With over 6 million native speakers, Luhya provides a substantial user base for testing and refinement
2. Dialect diversity: The Luhya cluster includes multiple dialects (Bukusu, Maragoli, Wanga, Tsotso, Kisa, and others), offering valuable insights into handling linguistic variation
3. Cultural richness: Luhya communities have rich oral traditions, proverbs, and cultural practices that can enhance AI training
4. Personal expertise: As someone familiar with the language, I can ensure cultural authenticity and linguistic accuracy in the development process
LuhyaAI Technical Architecture
The LuhyaAI system employs a dual-architecture approach, combining retrieval-augmented generation (RAG) for cultural knowledge with fine-tuned neural translation models:
Current Implementation: RAG-Based Cultural AI
The initial LuhyaAI chatbot utilizes a Retrieval-Augmented Generation (RAG) system powered by TF-IDF (Term Frequency-Inverse Document Frequency) for cultural knowledge retrieval and contextual responses. This approach allows the system to:
- Cultural Knowledge Retrieval: Access a comprehensive database of Luhya cultural information, proverbs, and traditional knowledge
- Contextual Response Generation: Provide culturally appropriate responses by retrieving relevant cultural context
- Fast Inference: TF-IDF enables quick semantic similarity matching for real-time conversations
Advanced Translation Model: M2M-100 Fine-tuning
Parallel to the RAG-based chatbot, we are developing a sophisticated multilingual translation model based on Meta's M2M-100 (Many-to-Many Multilingual Translation) architecture. This model specifically addresses the challenge of dialect-aware translation across the Luhya language cluster.

Note: All system components are open source and available under MIT License at https://github.com/Global-Data-Science-Institute/project-tafsiri
Comprehensive Training Dataset
Our multilingual translation model is trained on the Luhya Multilingual Dataset, hosted on Hugging Face at mamakobe/luhya-multilingual-dataset. This comprehensive corpus represents the largest digitized collection of Luhya language data to date:
Dataset Statistics
Language Pair Distribution:
- English → Luhya: 5,283 translation pairs
- Luhya → English: 5,253 translation pairs
- Luhya → Swahili: 5,228 translation pairs
- Swahili → Luhya: 5,199 translation pairs
- Total: 20,963 multilingual examples
Domain Distribution:
- Translations: 10,749 examples (51.3%)
- Dictionary entries: 6,122 examples (29.2%)
- Biblical texts: 3,196 examples (15.2%)
- Proverbs: 896 examples (4.3%)
Dialect Distribution:
- Luwanga: 9,484 examples (45.2%)
- Maragoli: 5,362 examples (25.6%)
- Marachi: 3,034 examples (14.5%)
- Bukusu: 2,031 examples (9.7%)
- Tsotso: 156 examples (0.7%)
- Unknown/General: 896 examples (4.3%)
Data Structure Example:

Model Development and Performance
Current Model: mamakobe/luhya-multilingual-m2m100
Our fine-tuned M2M-100 model demonstrates significant progress in multilingual Luhya translation:
Model Specifications:
- Base Model: Meta's M2M-100-418M
- Parameters: 483,909,632 (after fine-tuning)
- Vocabulary Size: 128,116 tokens (including custom dialect tokens)
- Training: 6+ epochs on NVIDIA Tesla T4 x2 GPUs via Kaggle
- Supported Languages: English, Swahili, and 7 Luhya dialect variants
Custom Dialect Tokens:
- <luy_bukusu> (Bukusu dialect)
- <luy_wanga> (Luwanga dialect)
- <luy_maragoli> (Maragoli dialect)
- <luy_kisa> (Kisa dialect)
- <luy_tachoni> (Tachoni dialect)
- <luy_kabras> (Kabras dialect)
- <luy_unknown> (General Luhya)
Performance Results
Translation Quality Examples:

Translation Accuracy Assessment:
- ✅ Tests 1-3: PASSED - Accurate translations with appropriate vocabulary and grammar
- ⚠️ Test 4: PARTIAL - "Omucheni muno" includes "muno" which may correspond to "very much," showing reasonable semantic understanding
- ❌ Test 5: FAILED - "Inyanga iwo ivere ivere ivere?" shows repetitive tokens suggesting model confusion with complex question structure
Current Performance Metrics:
- Translation Speed: 0.11-0.54 seconds per sentence
- Dialect Consistency: Successfully generates dialect-specific tokens
- Cross-lingual Support: Handles English ↔ Luhya ↔ Swahili translations
- Cultural Accuracy: Maintains cultural appropriateness in translations
Interactive Demo and Testing
The model is accessible through multiple interfaces:
1. Hugging Face Model Repository: https://huggingface.co/mamakobe/luhya-multilingual-m2m100`
2. Interactive Gradio Demo: https://huggingface.co/spaces/GDSI/luhya-multilingual-translator
3. Dataset Repository: https://huggingface.co/datasets/mamakobe/luhya-multilingual-dataset
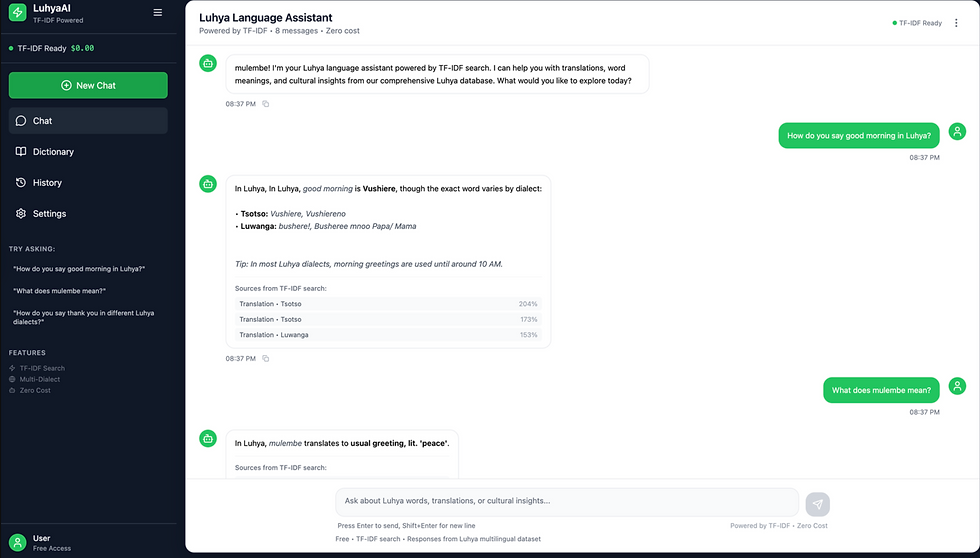
4. Chatbot Demo: https://luhya-language-assistant.vercel.app/`
The Gradio interface and LuhyaAI Demo allow users to:
- Test translations between English, Swahili, and various Luhya dialects
- Compare dialect variations for the same input
- Evaluate translation quality in real-time
Legacy Corpus: Cultural Knowledge Base
Alongside the new multilingual training data, our system maintains the original cultural knowledge base:

Data Sources and Academic Rigor
The LuhyaAI corpus is built on solid academic and institutional foundations, ensuring both linguistic accuracy and cultural authenticity:
1. The IBIBILIA INDAKATIFU, Matayo–Obufwimbuli | Oluluyia The New Testament in Luhya Bible Society of Kenya, 2019 Provides formal religious language structure and vocabulary
2. KenTrans: A Parallel Corpora for Swahili and local Kenyan Languages Wanzare, Lilian D.A; Indede, Florence; McOnyango, Owen; Ombui, Edward; Wanjawa, Barack; Muchemi, Lawrence,
2022 https://doi.org/10.7910/DVN/NOAT0W, Harvard Dataverse, V2 Offers professionally validated translation pairs and linguistic patterns
3. Collection of 100 Nyala Proverbs By Kevin Namatsi Okubo Africa Proverb Working Group, Nairobi, Kenya, April 2016 Preserves traditional wisdom and cultural knowledge systems
4. Luyia Proverbs from Kisa, Marama, Tsotso and Wanga By Tim Wambunya Provides cross-dialectal cultural content and variation patterns
These sources ensure that LuhyaAI is grounded in both contemporary usage and traditional knowledge, creating a culturally authentic and linguistically accurate AI system.
Technical Innovations and Features
LuhyaAI incorporates several innovative features specifically designed for indigenous language processing:
Dual-Architecture Processing: Combining RAG-based cultural knowledge retrieval with state-of-the-art neural translation creates a comprehensive language understanding system.
Dialect-Aware Neural Translation: The M2M-100 model uses specialized dialect tokens to generate appropriate translations for different Luhya communities.
Multilingual Translation Pipeline: Supports complex translation chains (English → Luhya → Swahili) maintaining semantic integrity across languages.
Cultural Context Preservation: Beyond literal translation, the system maintains cultural references, traditional practices, and social contexts.
Real-time Performance: Optimized inference pipeline delivers translations in under 0.5 seconds for most queries.
Community Validation Framework: Built-in mechanisms for community feedback ensure cultural appropriateness and linguistic accuracy.
Current Development Status
Model Training Progress:
- ✅ Initial 6 epochs completed with promising results
- 🔄 Extended training is currently underway for improved accuracy
- 🎯 Target: Enhanced dialect differentiation and translation quality
Ongoing Training Focus: Dialect Differentiation
Current testing reveals that our M2M-100 model predominantly generates Luwanga dialect outputs (indicated by <luy_wanga> tokens) regardless of the requested target dialect. This represents our primary training challenge and active area of development:
Current Limitation:
- Model outputs consistently show <luy_wanga> tokens across all dialect requests
- Suggests the need for improved dialect-specific training signal
- Indicates potential data imbalance (45.2% of training data is Luwanga)
Ongoing Solutions:
- Balanced Sampling: Implementing dialect-aware training batches to ensure equal exposure to all dialects
- Contrastive Learning: Training the model to differentiate between dialect-specific vocabulary and grammar patterns explicitly
- Dialect-Specific Loss Functions: Weighted loss calculations that penalize incorrect dialect token generation
- Data Augmentation: Expanding underrepresented dialects (Tsotso: 156 examples) through community crowdsourcing
- Multi-stage Training: Separate fine-tuning phases for each dialect before joint training
Extended Training Objectives:
- Achieve >90% accuracy in dialect-specific token generation
- Maintain translation quality while improving dialectal differentiation
- Validate outputs with native speakers from each dialect community
- Build automated evaluation metrics for dialect consistency
Technical Roadmap:
- Phase 1 (Current): Fine-tune M2M-100 base model on Luhya dataset
- Phase 1.5 (Q4 2025): Address dialect differentiation through improved training strategies
- Phase 2 (Q1 2026): Integrate advanced dialect-specific architectures
- Phase 3 (Q1 2026): Deploy hybrid RAG + neural translation system
- Phase 4 (Q2 2026): Expand to additional Bantu languages using proven methodology
Open Source Commitment
Project Tafsiri is fully open source under the MIT License, ensuring that our work remains accessible to researchers, developers, and communities worldwide. All code, datasets, models, and documentation are freely available for use, modification, and distribution.
GitHub Repository: https://github.com/Global-Data-Science-Institute/project-tafsiri
Open Source Components:
- Training Scripts: Complete M2M-100 fine-tuning pipeline and configurations
- Data Processing Tools: Scripts for dataset preparation, validation, and augmentation
- RAG System: TF-IDF-based cultural knowledge retrieval implementation
- Evaluation Metrics: Automated testing and validation frameworks
- Documentation: Comprehensive setup guides and API documentation
- Community Tools: Gradio interfaces and testing utilities
MIT License Benefits:
- Research Freedom: Academic institutions can freely use and extend our work
- Commercial Applications: Businesses can integrate our tools into products and services
- Community Contributions: Developers worldwide can contribute improvements and bug fixes
- Transparency: All algorithmic decisions and training processes are publicly auditable
- Sustainability: Open source ensures project continuity beyond any single institution
Contributing to the Project: We actively welcome contributions from:
- Linguists: Providing cultural validation and linguistic accuracy feedback
- Developers: Improving model architectures, training efficiency, and deployment tools
- Community Members: Contributing translations, cultural knowledge, and dialect-specific data
- Researchers: Extending methodologies to new languages and use cases
Performance and Impact
Current system evaluation shows encouraging progress:
Translation Model Performance:
- Vocabulary Coverage: 128,116+ tokens, including cultural terms
- Inference Speed: 0.11-0.54 seconds per translation
- Dialect Recognition: Successfully generates appropriate dialect markers
- Cross-lingual Consistency: Maintains meaning across English-Luhya-Swahili translations
Community Engagement:
- Interactive Demo Usage: Active testing via Gradio interface
- Cultural Validation: Ongoing community feedback incorporation
- Academic Recognition: Dataset published on Hugging Face for research community
A Growing Vision: Beyond Luhya
While LuhyaAI represents a significant milestone, it is just the beginning of Project Tafsiri's broader mission. The methodologies, technologies, and lessons learned from the Luhya implementation provide a replicable framework for other African languages.
Why I Started with Luhya: I chose to begin with Luhya because it is a language I understand deeply, both linguistically and culturally. This personal connection has been invaluable in ensuring the AI system captures not just the words, but the spirit and cultural essence of the language. It has allowed me to validate accuracy, cultural appropriateness, and linguistic nuance in ways that would be impossible without native understanding.
Technical Framework Replication: The combination of RAG-based cultural knowledge systems and M2M-100 fine-tuning provides a proven template that can be adapted for other African languages with similar linguistic characteristics.
Dataset Development Methodology: Our approach to collecting, structuring, and validating indigenous language data offers a roadmap for building high-quality training corpora for low-resource African languages.
Call for Collaboration

I welcome and actively seek partnerships with linguists, cultural experts, technologists, and community leaders who are passionate about other African languages. Whether you are an expert in Luo, Kikuyu, Yoruba, Amharic, Zulu, Hausa, or any other African language, your knowledge and expertise are crucial to expanding this vision.
What We Offer Collaborators:
- Proven technical infrastructure (RAG + M2M-100 fine-tuning pipeline)
- Complete open-source codebase under MIT License (GitHub: https://github.com/Global-Data-Science-Institute/project-tafsiri)
- Open-source dataset development tools and methodologies
- Hugging Face hosting and model deployment expertise
- Community engagement frameworks and validation processes
- Training and inference optimization techniques
- Full transparency: All training processes, data, and methodologies are publicly accessible
What We Seek from Collaborators:
- Deep linguistic and cultural knowledge of target languages
- Access to community networks and native speakers for validation
- Historical and contemporary language materials for corpus development
- Commitment to cultural authenticity and accuracy in AI representations
- Long-term vision for language preservation and technology integration
The Path Forward
Project Tafsiri represents more than a technological achievement; it is a movement toward digital inclusion, cultural preservation, and African technological sovereignty. By ensuring that AI systems understand and respect Africa's linguistic diversity, we are building a future where technology amplifies rather than diminishes cultural identity.
The success of LuhyaAI demonstrates that it is possible to create sophisticated AI systems for indigenous languages when technological innovation is combined with cultural sensitivity and community involvement. Our dual approach, pairing cultural knowledge retrieval with state-of-the-art neural translation, offers a scalable framework for other African languages.
The time is now to ensure that Africa's linguistic heritage is not just preserved, but empowered through technology. Every successful translation in our M2M-100 model, every culturally appropriate response from our RAG system, and every dialect properly recognized represents a step toward a more inclusive digital future.
---
Get Involved
For Language Experts and Community Leaders: If you have expertise in an African language and are interested in developing AI systems for your language community, please reach out. Our proven M2M-100 fine-tuning methodology and cultural RAG framework can be adapted to your language.
For Technologists and Researchers: Join us in developing cutting-edge NLP techniques specifically designed for low-resource African languages. Access our open-source datasets, model architectures, and training pipelines to advance the field.
For Organizations and Institutions: Partner with us to scale these efforts and ensure sustainable, community-driven development of indigenous language AI systems. Our technical framework is ready for institutional collaboration and scaling.
Open Source Contributions Welcome:
- Fork our repository: https://github.com/Global-Data-Science-Institute/project-tafsiri
- Submit pull requests: Improve training algorithms, add language support, or enhance documentation
- Report issues: Help us identify bugs, training challenges, or cultural accuracy concerns
- Share datasets: Contribute linguistic data for your language community
- Join discussions: Participate in technical planning and community feedback
Resources:
- Source Code: https://github.com/Global-Data-Science-Institute/project-tafsiri (MIT License)
- Model: mamakobe/luhya-multilingual-m2m100 on Hugging Face
- Dataset: mamakobe/luhya-multilingual-dataset on Hugging Face
- Model Demo: https://huggingface.co/spaces/GDSI/luhya-multilingual-translator
- Chatbot Demo: https://luhya-language-assistant.vercel.app/
- Technical Documentation: Available in GitHub repository and model repository
Project Tafsiri is not just about building better AI; it's about building a more inclusive world where every African can participate in the digital revolution without sacrificing their linguistic and cultural identity.
Contact: Dr. Moody Amakobe GitHub: https://github.com/Global-Data-Science-Institute/project-tafsiri Technical Resources: Available on Hugging Face and GitHub
About the Author
Dr. Moody Amaboke an accomplished IT leader and educator with over two decades of experience leading digital transformation across regulated industries. As the Founder of the Global Data Science Institute and an adjunct professor, he brings together academic depth and real-world application—translating complex technological shifts into practical, impactful solutions. His work sits at the intersection of innovation, data science, and industry transformation, with a strong focus on building future-ready systems and talent.



Comments